黄华威,2026年5月3号
HuangLab 并不高产,但足够专注:近5年专注于研究区块链底层原理与技术,尤其聚焦于分片区块链 (Blockchain Sharding) 的理论与技术架构。
2026年4月28日,中山大学软件工程学院黄华威研究组 (HuangLab) 在区块链可扩展性领域的3篇最新论文被分布式计算领域国际会议 IEEE International Conference on Distributed Computing Systems (ICDCS) 2026 接收。ICDCS 是分布式计算与系统领域的 CCF-B 类国际会议,发表分布式系统、区块链、云计算等前沿研究。本次 ICDCS 2026 论文接收率是18.59%。

HuangLab被接收的这3篇论文分别从区块链的 “存储卸载”与“共识解耦”、跨分片交易公平性优化、跨分片交易低延迟原子性 三个维度,有望系统性地推进区块链分片技术的研究边界。
接收论文信息
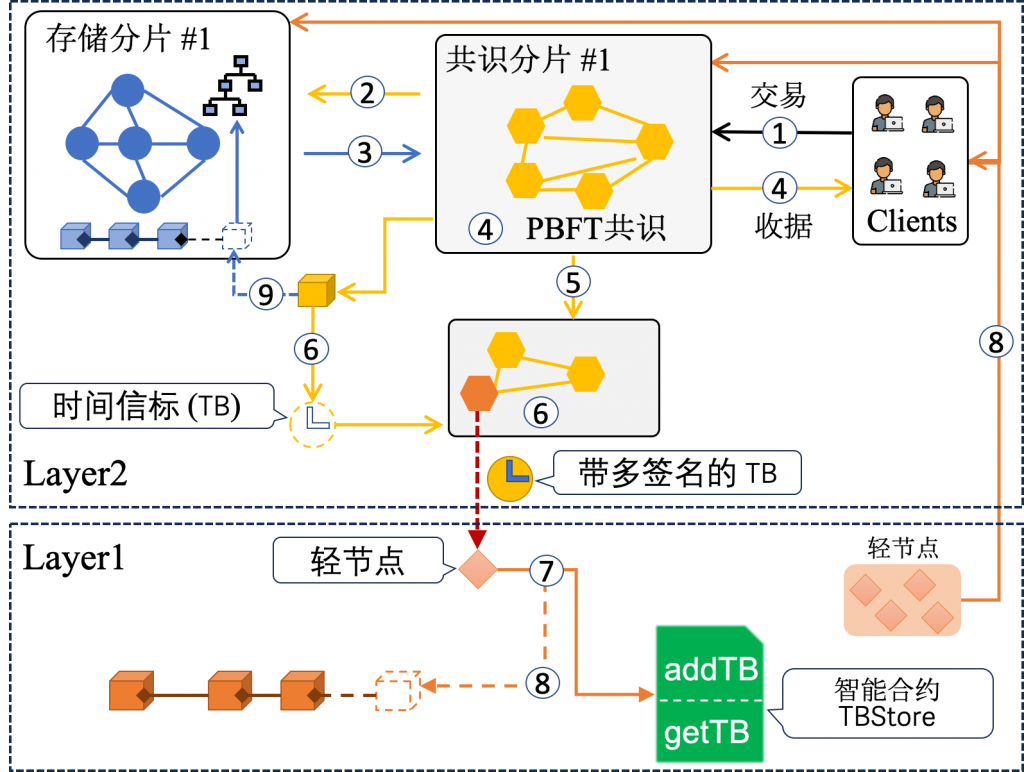
论文一:Folium —— 通过 Follower 节点解耦交易执行与共识
Xiaofei Luo, Huawei Huang*(黄华威,通讯作者), Jian Zheng, Baozhou Xie, “Folium: Decoupling Transaction Execution from Consensus via Follower Nodes in a Blockchain,” in Proc. of IEEE International Conference on Distributed Computing Systems (ICDCS), 2026.
关键词: 区块链可扩展性、存储卸载、共识解耦、轻节点参与
核心贡献:
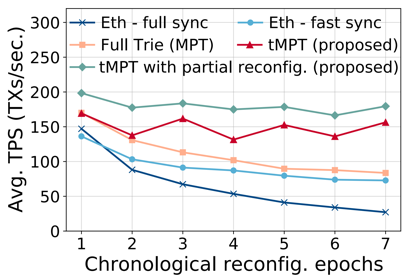
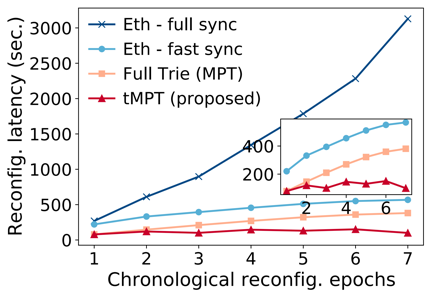
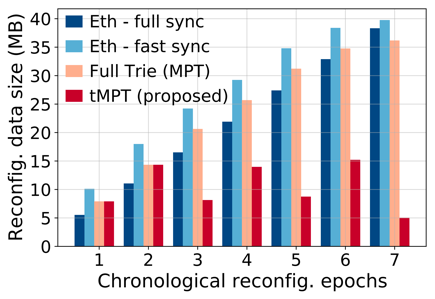
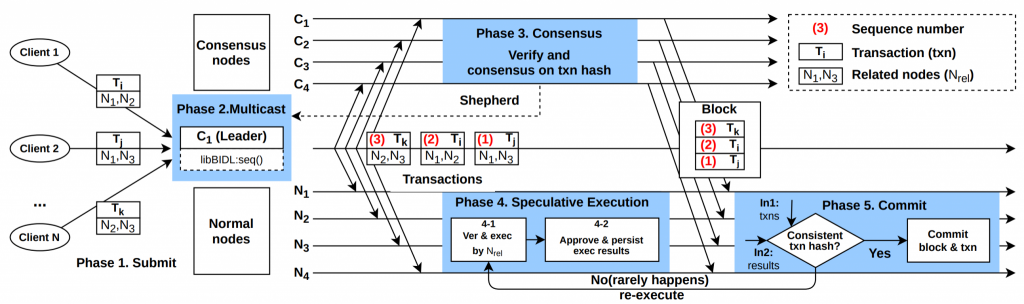
Folium 提出了一种全新的 Proposer-Follower区块链架构,旨在升级当前主流区块链的架构设计。在 Folium 中,异构的低资源节点可以作为特定 Proposer(全节点)的 Follower 加入网络。Folium 使 Proposer 能够将交易执行和账本状态存储卸载给 Follower 节点,从而大幅降低全节点的存储开销,提升共识效率和交易吞吐量。
Folium 的核心设计包含:
- 确定性 MPT 分区方案:Proposer 基于哈希账户密钥将全局状态树划分为多个不重叠区间,分配给不同 Follower;
- 去中心化交易调度机制:支持批处理调度和流式调度两种模式,实现并行执行;
- 去中心化交易调度机制:通过激励层、质押承诺层、奖励分配层三层设计,确保 Proposer 与 Follower 之间的安全协作;
- 动态负载均衡:根据历史交易统计动态调整交易路由,适配异构设备的处理能力。
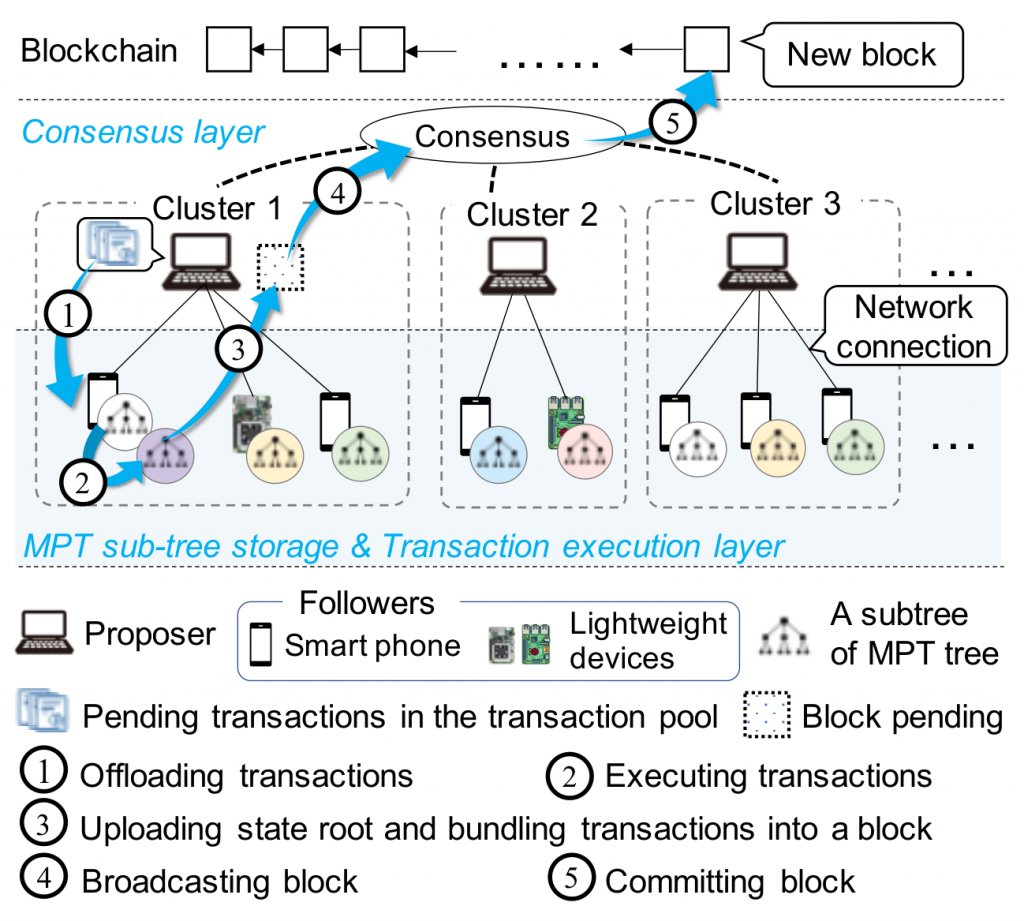
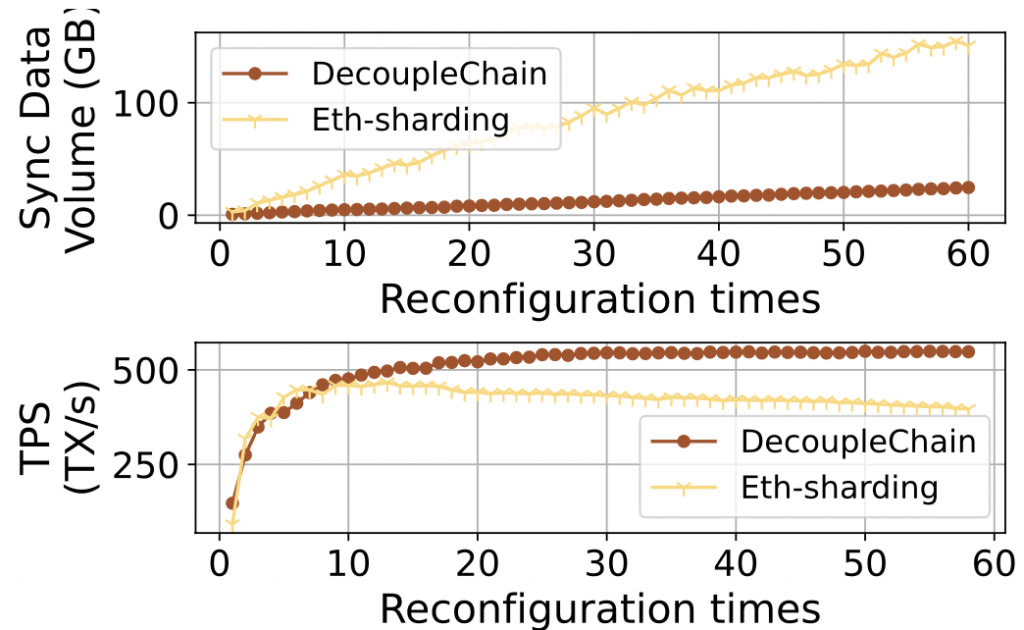
实验结果表明,Folium 能够将交易执行延迟降低 60% 以上,吞吐量提升 4 倍,全节点账本存储降低 80% 以上(在 10 个 Follower 配置下)。Folium 已在分片区块链(Monoxide)、以太坊单链架构、PBFT 单链架构三种典型区块链上实现验证,并支持异构设备(Raspberry Pi、TPU 板、Mini PC 等)的真实部署。
论文二:Justitia-L —— 基于拉格朗日对偶控制的预算约束公平性优化
Sihua Wang (本科3年级同学), Jian Zheng, Huawei Huang*(黄华威,通讯作者), “Justitia-L: Budget-Constrained Fairness Optimization in Sharded Blockchains via Lagrangian Dual Control,” in Proc. of IEEE International Conference on Distributed Computing Systems (ICDCS), 2026.
关键词: 区块链分片、拉格朗日对偶控制、代币经济学、经济可持续性
核心贡献:
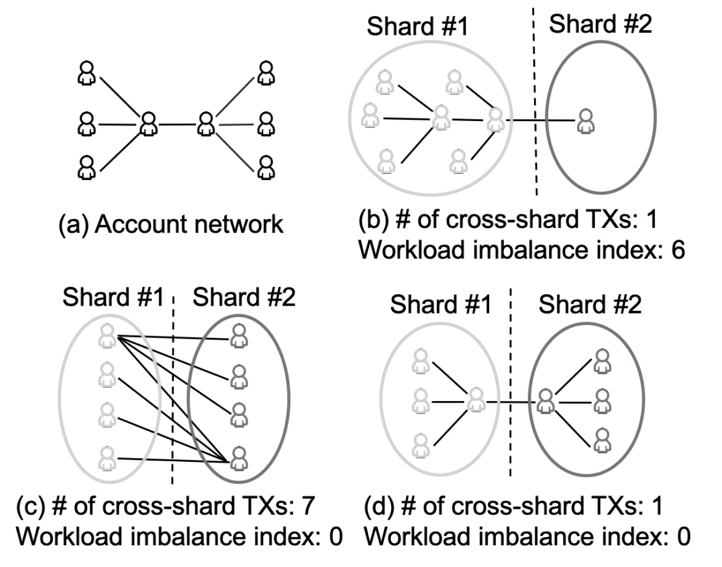
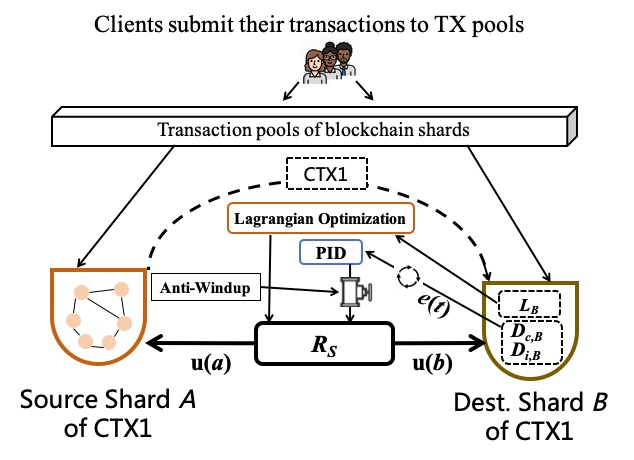
区块链分片中,跨分片交易(CTXs)与片内交易(ITXs)存在天然的优先级差异,导致持久性的处理不公平,这是制约系统性能的关键瓶颈。传统激励机制(如 Justitia)主要依赖开环或半动态设计,在波动负载下无法维持控制精度,且缺乏针对代币通胀的严格经济保障。
Justitia-L 提出了一种分层自适应激励框架,将微观层面的延迟纠正与宏观层面的预算管理解耦:
- Justitia-PID 模块:采用闭环反馈控制律,将 CTX 与 ITX 的块级排队延迟偏差驱动至零;
- 拉格朗日对偶优化层:将公平性优化建模为约束拉格朗日对偶问题,引入动态“影子价格”(Shadow Price, λ)来调节激励强度相对于全局通胀预算的关系。
这种双层架构使系统既能敏捷应对瞬态流量突发,又严格遵循长期经济安全边界。理论分析证明了系统的全局渐近稳定性、纳什均衡激励相容性和预算安全性。
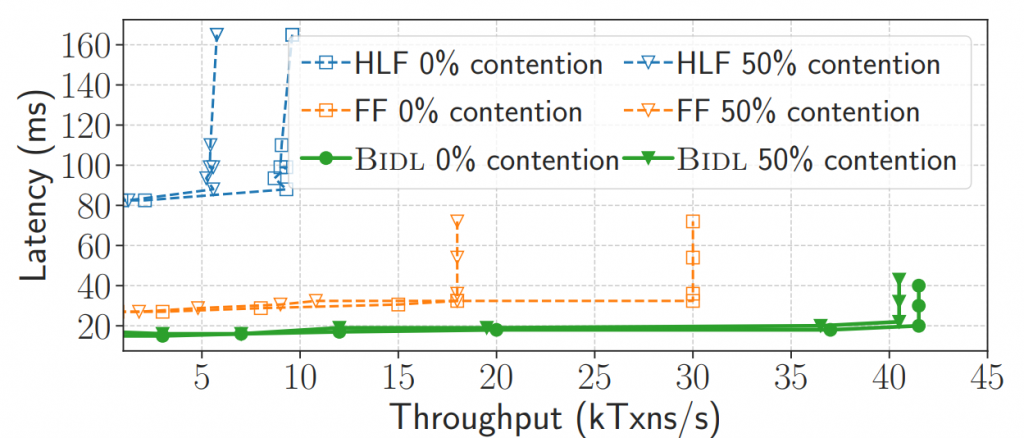
实验使用真实以太坊历史交易数据(25万笔交易)在 BlockEmulator 上验证,结果表明 Justitia-L 将 CTX 的尾延迟降低 74%,实现了接近最优的延迟比率 0.98×,在响应精度和通胀鲁棒性方面显著优于现有启发式方案。
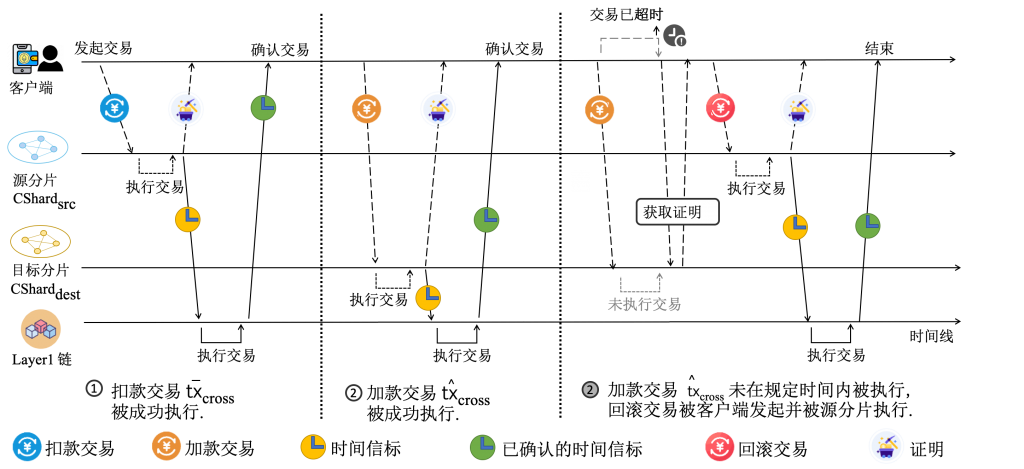
论文三:LLA —— 面向分片区块链跨分片交易的低延迟原子性调度
Huawei Huang*(黄华威,通讯作者), Jian Zheng, Qinde Chen, Yuting Yang, “Aiming Low-Latency Atomicity for Cross-Shard Transactions in a Sharding Blockchain,” in Proc. of IEEE International Conference on Distributed Computing Systems (ICDCS), 2026.
关键词: 区块链分片、跨分片交易、低延迟原子性、在线调度、排队论
核心贡献:
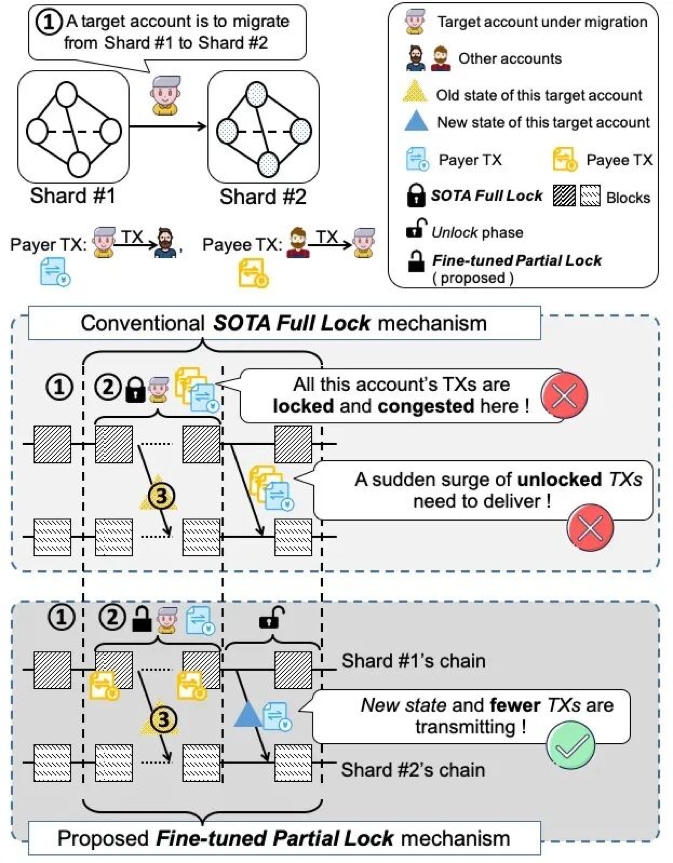
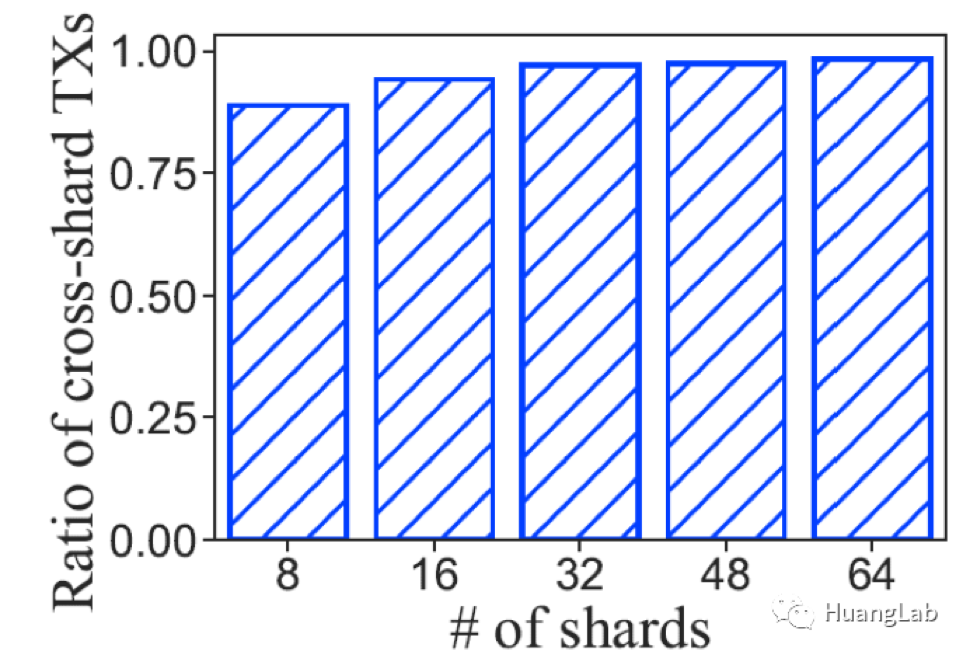
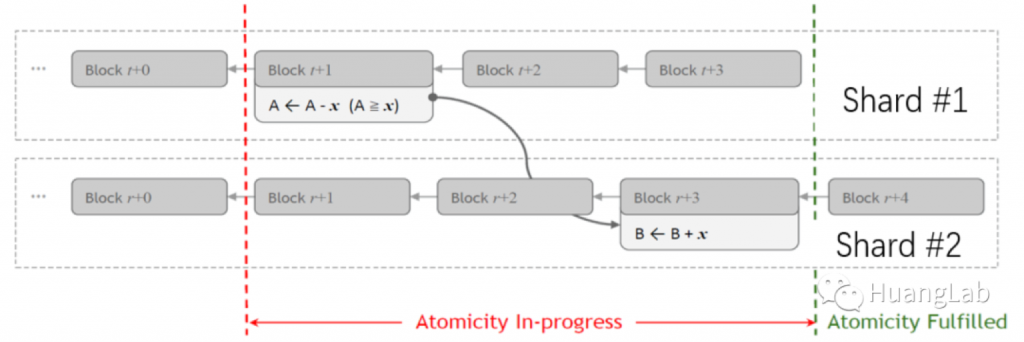
在分片区块链中,每笔跨分片交易(CTX)被拆分为两个子交易(sub-CTX1 和 sub-CTX2),分别需要在源分片和目标分片进行共识确认。这种“跨分片重复共识”导致 CTX 的确认延迟远高于片内交易(ITX),且保证原子性(两个子交易同时确认或同时失败)是一个重大技术挑战。
LLA(Low-Latency Atomicity)提出了一种去中心化在线调度算法:
- 抢占式排队模型:利用 Lyapunov 优化理论将全局离线调度问题转化为各分片可独立执行的在线优化问题;
- 抢占式排队模型:每个分片基于本地观测状态实时决策交易包含策略,无需全局协调;
- 理论保证:证明了算法具有 O(1/V) 的最优性间隙,且能稳定多队列分片区块链系统。
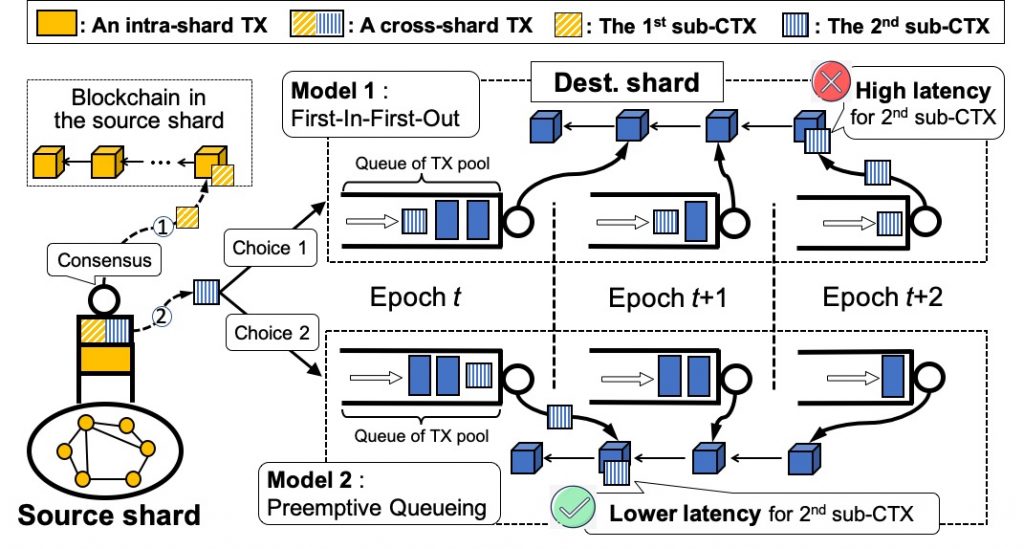
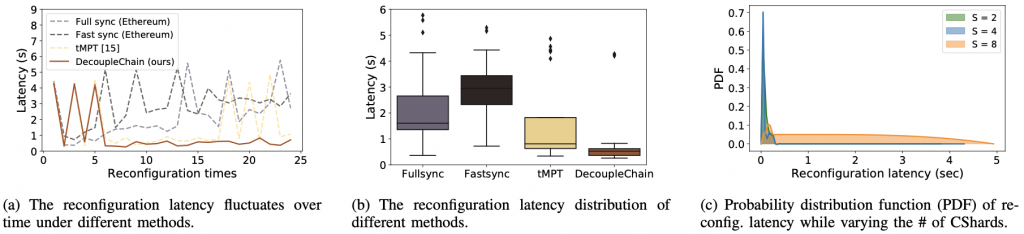
实验在开源测试平台 BlockEmulator 上进行,结果表明:
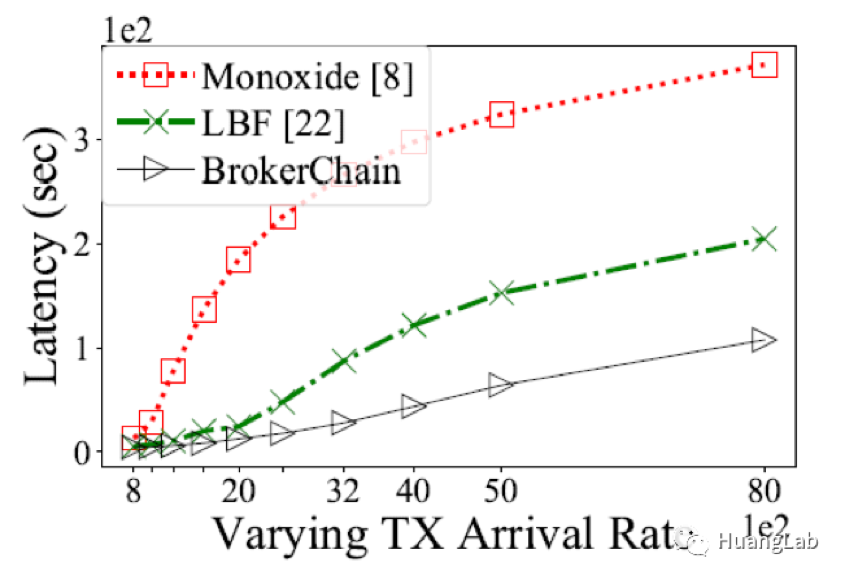
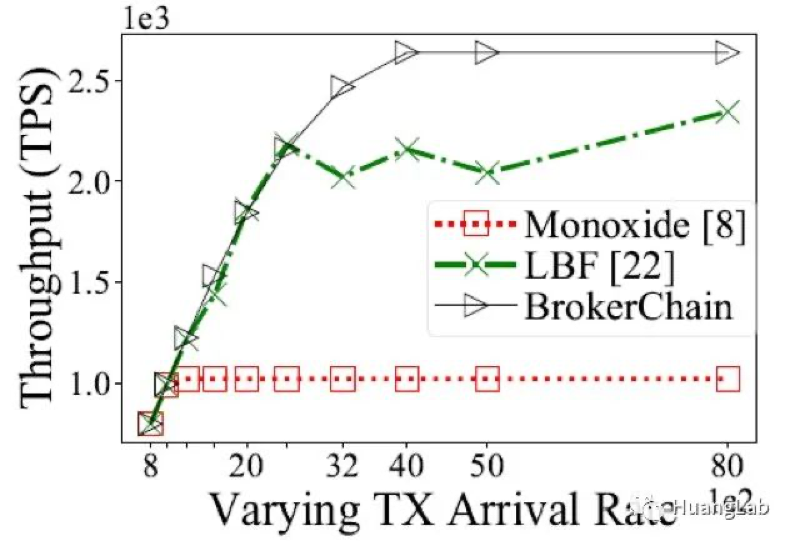
- 与经典分片协议 Monoxide 相比,CTX 平均延迟降低 70.8%(32 分片配置下);
- sub-CTX2 的排队延迟稳定在 1-2 个 epoch,显著优于 Monoxide 和 DelayFirst 基线方案;
- 算法执行时间几乎可以忽略不计,具备大规模系统部署的可行性。
论文预印本下载
3篇论文的网盘文件夹访问链接:HuangLab-3-Papers-accepted-by-ICDCS-2026
链接: https://pan.baidu.com/s/1NLqR57JeyYCHKRSIAdPkBQ?pwd=1234
第1篇论文(Luo2026Folium)下载链接:
通过网盘分享的文件:Luo2026Folium.pdf
链接: https://pan.baidu.com/s/1V_BMtEOiS6AdSDNyTvO1lg?pwd=1234
第2篇论文(Wang2026Justitia-L)下载链接:
通过网盘分享的文件:Wang2026JustitiaL.pdf
链接: https://pan.baidu.com/s/1RyoRGvOMPMjgxprTvy-5Yg?pwd=1234
第3篇论文(Huang2026LLA)下载链接:
通过网盘分享的文件:Huang2026LLA__Aiming_LLA_for_CTXs_in_Sharding_Blockchain.pdf
链接: https://pan.baidu.com/s/1ST7f1TGkP_DrV9ftrc5scg?pwd=1234
也可在 HuangLab 公众号(ID: Huang-Lab)后台发送消息 “ICDCS2026”,获取3篇论文 zip打包下载链接。
开源工具的使用
这三篇论文使用的实验平台 BlockEmulator 是中山大学黄华威教授研究组(HuangLab)开发并开源的一款区块链性能测试工具,支持以太坊交易回放、多分片仿真、协议自定义、可二次开发等功能,已被全球90多个国家的研究者访问使用。研究组于2026年4月初公布了一个更好用的加强版本 BlockEmulator-X (即 BlockEmulator v2.0 版本),功能更加强大,欢迎试用。
- BlockEmulator 主页:https://www.blockemulator.com/
- BlockEmulator v1.0 的GitHub 仓库:https://github.com/HuangLab-SYSU/block-emulator
- BlockEmulator v2.0 的GitHub 仓库:https://github.com/HuangLab-SYSU/block-emulator-x
其技术论文 “BlockEmulator: An Emulator Enabling to Test Blockchain Sharding Protocols” 发表在 IEEE TSC,已得到多次引用。欢迎跳转了解 BlockEmulator《区块链实验平台 BlockEmulator 投稿 TSC 的故事》。
展望
HuangLab 这三篇 ICDCS 2026 论文从不同维度系统性地推进区块链技术的研究:
- Folium 为区块链架构升级提供了新思路,使低资源设备能够安全参与网络并分担计算与存储负载;
- Justitia-L 建立了分片区块链中经济可持续的公平性激励机制,为代币经济学设计提供了理论保障;
- LLA 从调度理论角度解决了跨分片交易原子性与低延迟的权衡难题,为高性能分片区块链的实用化铺平道路。
未来,HuangLab 团队将进一步探索智能合约分片、跨链互操作、区块链与 AI 融合等前沿方向,推动区块链技术的规模化落地。
致谢
感谢国家自然科学基金面上项目、广东省自然科学基金杰出青年项目的支持。感谢所有合作者与 BlockEmulator 开源社区贡献者的共同努力。
研究团队
本次三篇论文均由中山大学软件工程学院黄华威教授研究组(HuangLab)主导完成,HuangLab 研究组成员包括1位教授、2位在站博士后、若干位博士与硕士研究生、本科实习生。研究组长期专注于区块链底层系统与协议、区块链金融、分布式系统与计算、区块链与AI融合等方向的研究,已在 IEEE/ACM ToN、TPDS、TC、TIFS、TDSC、INFOCOM、WWW、ICDCS、SRDS 等顶级会议与期刊发表多篇区块链论文。黄华威教授近些年从事区块链可扩展性、区块链金融、区块链融合AI等领域的研究,著有《Blockchain Sharding: Theory and Practice》(Springer)、《From Blockchain to Web3 & Metaverse》(Springer)、《从区块链到 Web3》(科普书) 等多部专著。黄华威研究组研发并开源了区块链实验平台 BlockEmulator,该平台为区块链方向的研究者提供了成熟优质的实验方法、工具与开源代码,已得到90多个国家地区的研究者的访问或使用;牵头研发了分片区块链 BrokerChain 公链,于2025年6月上线了它的学术版测试网 BrokerChain Testnet (academic),已开源 ( https://github.com/HuangLab-SYSU/brokerchain-academic/ )。
若您对区块链、区块链与AI融合交叉研究等方向感兴趣,欢迎关注 HuangLab 公众号(ID: Huang-Lab)或访问 HuangLab 学术主页:http://xintelligence.pro